We enable your organisation to store, recognise and access the often untapped value of your data by providing tools and services for data insight and visualisation.
The evolution of data analytics
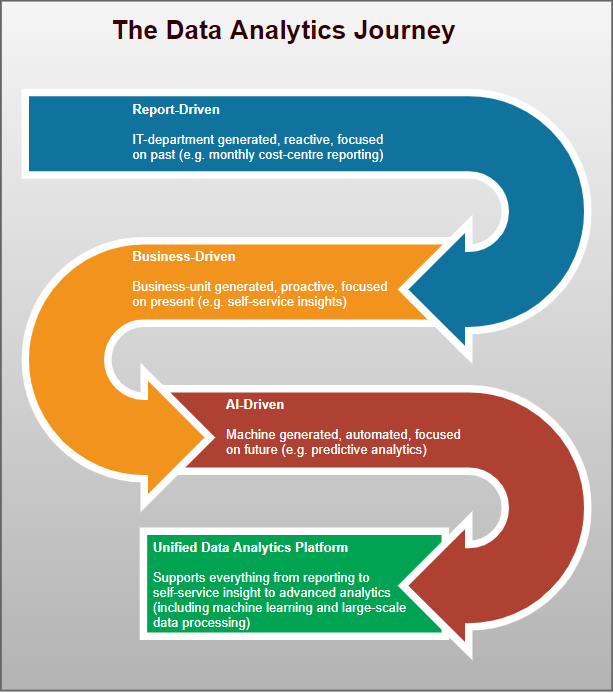
The analytics journey typically encompasses several phases, as illustrated in the following graphic:
In the report-driven phase, businesses are concerned with data quality, its integration, the creation of data warehouses, and the reporting and measurement of standard KPI's along with the creation of core dashboards.
The business-driven phase introduces the ability of business areas to determine and action their own reporting needs which results in the introduction of self-service tooling, accompanied by data management and report governance across the organisation.
The AI-driven phase may rely on data streaming to enable near real-time data feeds and change data capture and leverages data operations and data science methods with data across an organisation typically being pooled into a data lake. A high degree of data literacy may be needed to realise the potential of any data (i.e. being able to both semantically interpret data and act upon analytic output).
We are only at the dawn of the AI-driven phase in this evolutionary process. Many organisations have yet to progress to or fully exploit the potential of this stage. With this proliferation of analytics decision making possibilities, together with the inundation of data with which organisations are contending, technology broad enough to cater across the entire range of analytic needs is being introduced. Thus we see the arrival of the 'Unified Data Analytics Platform' commonly referred to as UDAP.
Taking a high-level holistic perspective to what a successful UDAP ought to enable an organisation to achieve, we are essentially looking at the following three abilities:
- An ability to seamlessly connect to data
- An ability to unify, orchestrate, and understand it
- An ability to leverage it for analytics
So, by connecting to all of the data in the disparate systems maintained by an organisation a 360-degree view of that data becomes possible.
By unifying, orchestrating and understanding it, one can provide appropriate 'semantic layers' or views of that data (i.e. the right data pieces for the right personas).
By leveraging the data for analytics everything from reporting, to self-service ad-hoc insights, to advanced analytics (machine learning and large-scale data processing) can be realised.
Technology evolution
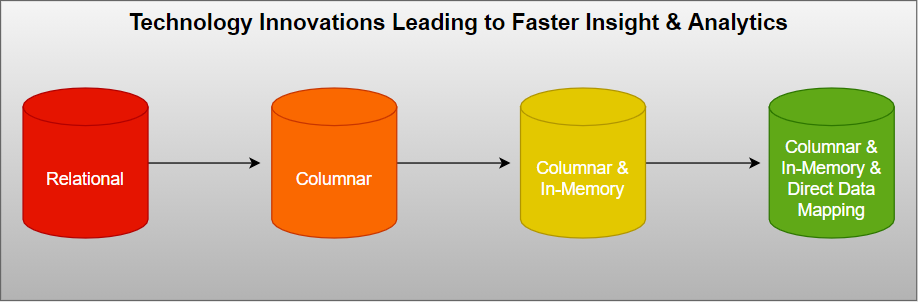
Early analytic technologies were based on standard relational databases which are great for storing data and transactional processing but not so performant for analysis operations.
This led to the introduction of columnar databases which are optimised for fast retieval of columns of data (rather than rows whose constituent attributes may not necessarily need to be accessed for the task in hand) - this drastically reduces the overall disk I/O requirement and the amount of data needing to be retrieved during analytics. The columnar nature enables such databases to effectively scale out using distributed clusters of low-cost hardware to increase throughput.
This further led to the development of in-memory columnar databases whereby the data being acted upon is entirely kept in memory thus eliminating waits for disk I/O and a speed improvement of several magnitudes.
These in-memory database engines are still subject to issues of joins between database tables which become increasingly CPU bound as the number of joins increases. As a result data modelling design techniques such as the use of star schemas and denormalisation of data when moving it between source transactional relational databases and data warehouses are in common use. This reshaping of data to enable faster aggregation inevitably loses the granular nature of the original data and leads to a complex ETL (Extract, Transform and Load) process.
The latest innovation which overcomes this limitation is the introduction of Direct Data Mapping Metadata to the columnar in-memory engine.
It solves a fundamental problem of relational databases - joins do not perform at scale. This results in the ability to eliminate the need for data modelling to reshape data and is capable of supporting queries across billions of rows in seconds. So, the technology innovation sequence is as follows:
Direct Data Mapping is a ground-breaking innovation from
Incorta. Kronva is an Incorta partner. We believe that Incorta is the Unified Data Analytics Platform of choice so we continue to invest both time and effort in our involvement with the product to ensure that our customers have the most expert help in deploying and exploiting what we regard as the most versatile and powerful general purpose warehousing and analytics tooling available today.
Learn more about Incorta below.
Incorta offers a radical, modern approach to the concepts of analytics and business intelligence. As an end-to-end analytics solution Incorta sources data, stores data, and provides a visualisation interface for analytics in a single Unified Data Analytics Platform. Here's an introductory overview:
Where traditional approaches require complex modelling and reshaping of data, Incorta, via its Direct Data Mapping technology, allows you to analyse data in its original shape and preserves the original data granularity. If the data source has 190 tables with 358 joins across billions of rows of data Incorta enables direct analysis of that data with all of the joins actioned dynamically with access to all of the detailed transactions. Analysis can include dynamic aggregations on data in seconds. There are no star or snowflake schemas or cubes involved.
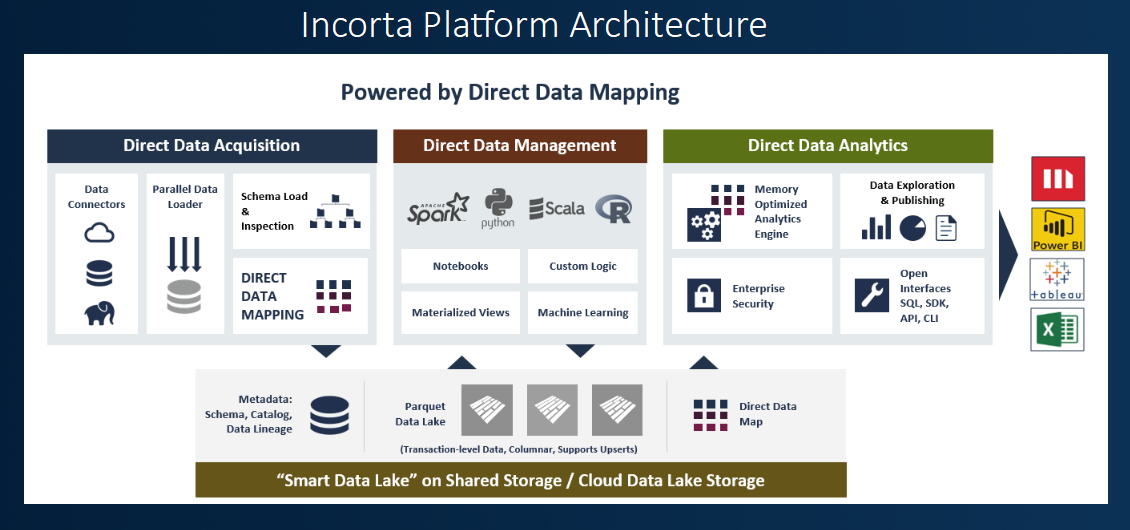
An overall appreciation of its key functional components is illustrated in the platform architecture:
By utilising data in its original shape, Incorta lets you deploy an analytic solution more simply and quickly than compared to traditional technologies.
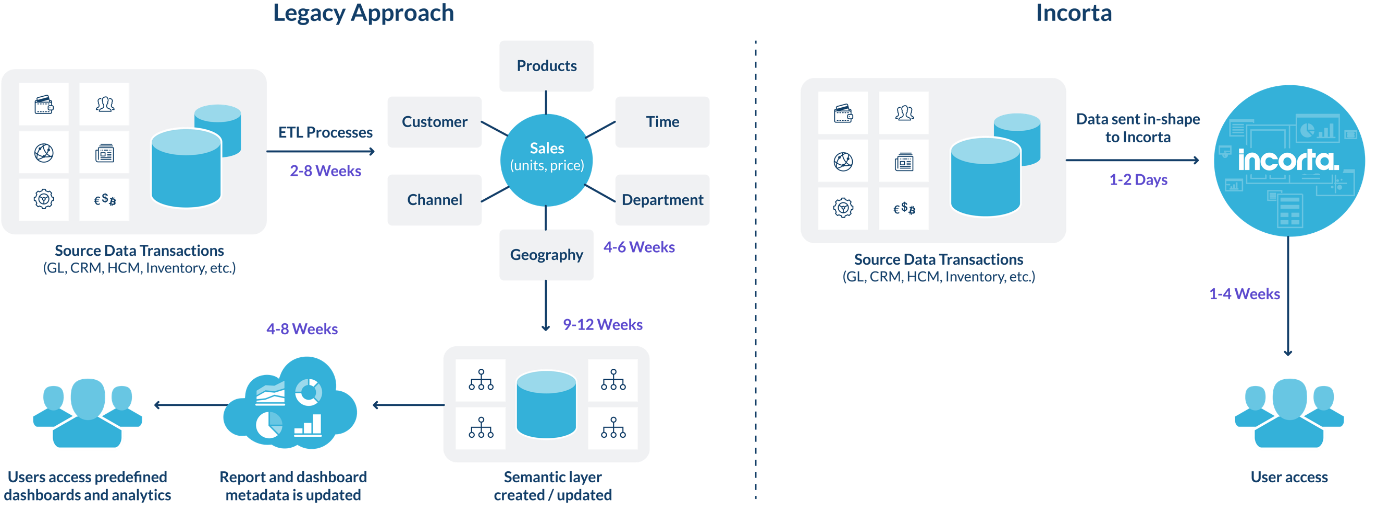
A traditional approach involves data extraction from the source system via an ETL tool, modelling of that data into a data warehouse structure, the creation of a semantic model, and the creation of reports and dashboards. Such a traditional deployment can take several months (20-44 weeks) or more.
Incorta removes the majority of these steps. Data is loaded in shape from the source. An optional semantic layer can be realised to group like data elements for analysis. Users can then leverage packaged and ad-hoc or self-service reporting. With Incorta deployments typically take a few weeks (4-6) in total.
Business Benefits
While Incorta's technology is revolutionary, the real business value comes from simplified deployment processes and effective, timely, use of data. Incorta:
-
Removes complex ETL by keeping data in shape for quick deployment times.
-
Is a modern data warehouse alternative - all transactional data is available for analysis and collaboration across the enterprise.
-
Allows users to leverage integrated search to filter and perform data discovery.
-
Supports near real-time data access via incremental loading.
-
Realises true end-user self-service and ad-hoc analysis - limited maintenance activities are required by IT.
-
Enables cleaning and enrichment of data from source systems without complex ETL or database resource.
Key Analytic Abilities
-
No Data Modelling and Instant Analytics - Incorta can aggregate high volumes of data and generate reports using a 3rd Normal Form (3NF) schema architecture nearly identical to your transactional databases.
-
Data remains compressed in operation - Incorta compresses data during ingestion and it remains compressed both on-disk and in-memory which makes it possible to analyse several times more data for a given memory capacity than alternatives which decompress data into memory. Source data also occupies less space than at its origin and compression speeds operational data transfer.
-
Dynamic Drill-Down - since data reshaping into predefined hierarchies and dimensions is not necessary, users can determine which columns to use when reporting without having to consider dimensionality. Its easy to change the drill down path for ad-hoc queries and 'what-if' questions.
-
Integrated Search - web-browser like search empowers users to easily uncover insights and analyse data at will. Unstructured data faceted search enables the discovery of hidden relevant data.
-
Inherited Application Security - because Incorta does not require reshaping of data, security can be applied in exactly the same way as in the source data systems. Incorta supports record-level, role, and object security. It integrates with SSO (Single Sign On) and advanced encryption standards.
-
Pluggable Data Sources - a pluggable data architecture integrates out-of-the-box with many of the database sources on the market today (Oracle, IBM, Microsoft, SAP HANA, etc.) and cloud applications (NetSuite, Salesforce, ServiceNow, etc). User datasets and Apache Kafka based streaming ingestion are also supported.
Data Science
Only one server with the proper resources will handle all BI duties (ETL, Data engine, visualisation, mobility, search and filter). In addition is the ability to extend and enrich the base data. This can be done by employing a set of business based heuristics to evaluate the existing data or by integrating expanded semi-structured datasets.
The highly extensible Incorta platform provides hooks into SQL and components such as Spark for metadata manipulation and enriched analysis. Incorta persists data in Parquet files (as used in any Hadoop ecosystem). These files are generated at data ingestion and can be stored in the Incorta file system or an existing data store. This enables the reading and mining of that data using processes such as Spark.
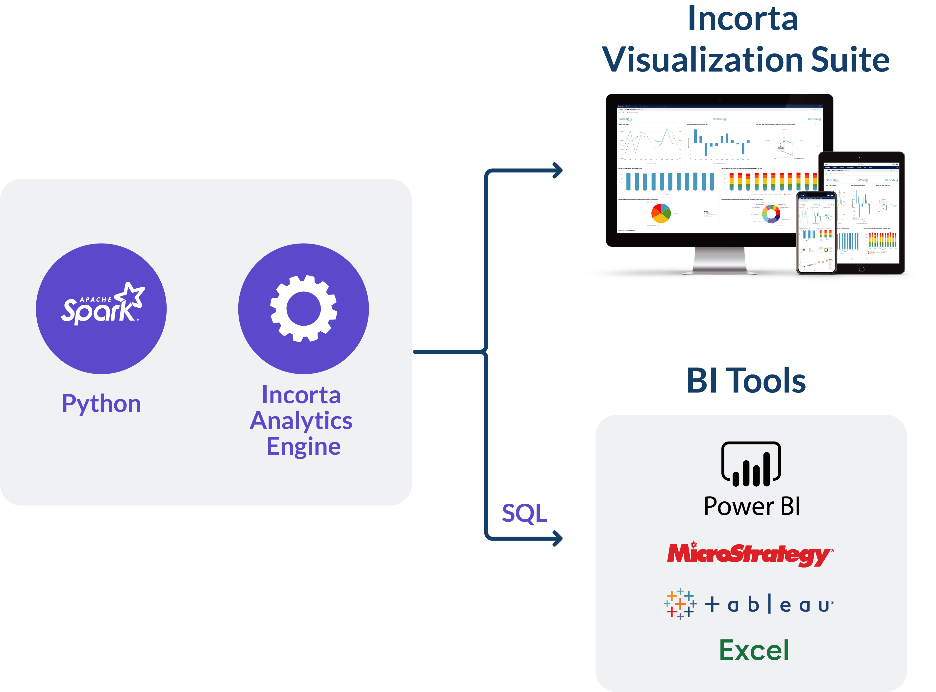
Data Visualisation
Incorta provides an end-to-end analytics platform handling data wrangling, cleansing, fast analytics, data science and both structured and ad-hoc data visualisation abilities.
To remove an adoption hurdle Incorta's architecture is designed to ensure that end consumers of data accessed through the Incorta engine can continue to use their preferred data visualisation tools whilst continuing to realise the incredible scale and efficiency of the product. This is enabled by supporting direct connectivity from those preferred BI tools to the groundbreaking Direct Data Mapping engine responsible for that efficency. Thus, if a user wishes to work with data in Tableau or MicroStrategy, they can direct those tools to an Incorta end-point and query that data live from Incorta.
Kronva and Incorta
As a recognised partner, we offer consulting and professional services for the Incorta platform, which is our recommended Unified Data Analytics Platform of choice.
If you're interested in a demonstration, considering a Proof of Value exercise, or simply wish to find out more please Get in Touch.